5清华大学0https://siyuanhuang.com/STRL0摘要0迄今为止,各种3D场景理解任务仍然缺乏实用且具有泛化能力的预训练模型,主要是由于3D场景理解任务的复杂性以及由相机视角、光照、遮挡等引入的巨大变化。在本文中,...
”3D点云时空表示学习 自监督学习 时空表示 3D场景理解 预训练模型“ 的搜索结果

分享视频教程——深度学习-3D点云实战系列,2021最新课程,完整版,附源码和数据集,想学习点云的同学抓紧时间下载了,很棒的一套课程
110252任意点云上三维特征的自监督预训练Zaiwei Zhang1,2*Rohit Girdhar1Armand Joulin1Ishan Misra11Facebook AI Research2德克萨斯大学奥斯汀摘要在大型标记数据集上进行预训练是在图像识别、视频理解等许多...
随着三维点云数据采集技术和传感器的普及和发展,基于深度学习的三维点云研究取得了长足进步。随着可访问数据集数量的增加,完全有监督的语义分割任务的准确性和有效性大大提高。这些方法训练神经网络,以更少的点...


3183用于自动驾驶罗晨旭1,2杨晓东...为此,我们提出了一个学习框架,该框架利用来自点云和配对相机图像的自由监督信号,纯粹通过自我监督来估计运动。我们的模型包括一个基于点云的结构一致性增强概率运动掩蔽以及跨传
由于室外3D场景的复杂性,在室外点云场景上进行手动注释是耗时且昂贵的。在本文中,我们研究如何实现场景理解有限的注释数据。将100帧连续图像作为一个序列,将整个数据集分成一系列序列,在每个序列的第一帧中只...
6423引导点对比学习半监督点云语义分割李江1史少帅1田卓涛1赖信1刘舒2傅志荣1贾亚嘉1,21香港中文大学2SmartMore@ [email protected]@ee.cuhk.edu.hk摘要3D语义分割的快速发展...




最近的工作已经证明了如何利用监督学习来学习更好和更紧凑的3D特征。然而,那些方法对地面实况注释的依赖限制了它们的可扩展性。我们建议BYOC:一种自我监督的方法,从RGB-D视频中学习视觉和几何特征,而不依赖于...

三维点云深度学习研究综述 论文:Deep Learning for 3D Point Clouds: A Survey 作者:Yulan Guo 时间:2019-12 引言 动机: Point cloud learning (点云学习)由于在视觉、自动驾驶、机器人等方面的广泛应用,...

到目前为止,各种 3D 场景理解任务仍然缺乏实用和可推广的预训练模型,这主要是由于 3D 场景理解的复杂性质及其由相机视图、照明、遮挡等带来的巨大变化。在本文中,我们通过引入时空表示学习(STRL)框架来应对这一...
7949C-Flow:图像和3D点云的条件生成流模型Albert Pumarola1,Stefan Popov2Francesc Moreno-Noguer1VittorioFerrari21InstitutdeRobo` ticaiInforma` ticaIndustrial,CSIC-UPC,Barcelona,Spain2GoogleResearch,...
受此成功的启发,我们研究了自注意网络在3D点云处理中的应用。我们设计了点云的自我注意层,并使用这些来构建自我注意网络的任务,如语义场景分割,对象部分分割,和对象分类。我们的点Transformer的设计改进,证明...

其主要贡献是通过由粗到细地计算两个框架之间的转移矩阵,将混沌引入搜索问题,在时间上扩展时形成多尺度对比随机游动这为光流、关键点跟踪和视频对象分割的自监督学习建立了统一的技术实验表明,对于这些任务中的每...
1035学习用于细粒度识别的规范3D对象表示Sunghun Joung1,Seungryong Kim2,Minsu Kim1,Ig-Jae Kim3,Kwanghoon Sohn1,*1延世大学、2高丽大学、3韩国科学技术研究院(KIST){sunghunjoung,minsukim320,khsohn}@ ...
111830基于MIL的弱监督点云分割杨正坤1吴季佳2陈凯宣2庄永玉1林燕玉2、31国立台湾大学2国立阳明交通大学3中央研究院摘要我们解决弱监督点云分割提出了一个新的模型,MIL派生的Transformer,挖掘额外的监督信号。...
而几何束调整缺乏定位不可见物体质心的能力为了利用深度神经网络强大的目标理解能力,同时解决精确的几何建模以实现一致的轨迹估计,我们提出了一种基于时空联合优化的立体3D目标跟踪方法。从网络中,我们检测相邻...
在正式讨论Transformer-XL之前,我们先来看看经典的Transformer(后文称)是如何处理数据和训练评估模型的,如所示。图1 Vanilla Transformer 训练和评估阶段在方面,给定一串较长的文本串,会按照固定的长度(比如...
76880C3DPO:非刚性结构运动的规范3D姿势网络0...α , θ )02D关键点和可见性0密集关键点0非刚性物体0刚性物体的单眼重建:0ϕ0图1:我们的方法通过无约束图像中的2D关键点学习可变形物体类别的3D模型。它包括一个深
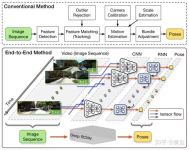
论文笔记:《Occ-BEV: Multi-Camera Unified Pre-training via 3D Scene Reconstruction》
推荐文章
- C语言排序算法_@c .sr.x,,]~~az-程序员宅基地
- JavaScript删除元素属性_$("#meterstatus").removeattr("readonly");-程序员宅基地
- 8. Vmvare中重新分配Linux系统的分区空间大小-程序员宅基地
- 电池管理系统中SOC算法的详解及优化_bms电池容量计soc-程序员宅基地
- 【卷积神经网络】卷积层,池化层,全连接层的理解_卷积层,池化层,全连接层-程序员宅基地
- “七网”融合发展的模式、系统架构及关键技术_七网融合-程序员宅基地
- Double转String避免科学计数法_防止double转换string变成科学-程序员宅基地
- 计算机毕业设计选题分享-springboot卡塔尔世界杯门户网站40685(赠送源码数据库)程序含:JAVA、PHP,node.js,C++、python,大屏数据可视化等-程序员宅基地
- 文件打包压缩及解压缩-程序员宅基地
- nacos 连不上数据库的一个坑_nacos 之前可以连数据库但是某天突然连不上了-程序员宅基地